gperftools是Google开源的一款包含多线程下高性能内存分配器tcmalloc和其他性能分析工具的集合。共分为四个部分,TCmalloc:一个优化的内存管理算法;Heap_Check:检测程序运行过程中是否发生内存泄漏的工具;Heap_Profile:监控程序运行过程中的内存分配情况的工具;Cpu_Profile:监控程序运行过程中的cpu消耗时间的工具;部分工具以treeline为例介绍其使用方法;
安装gperftools
安装所需工具
1 | sudo apt autoconf automake libtool |
安装libunwind
下载源码并解压
1 | wget http://download.savannah.gnu.org/releases/libunwind/libunwind-1.6.0.tar.gz |
编译并安装,默认安装在/usr/local目录下
1 | cd libunwind-1.6.0 |
安装图形可视化工具gv
1 | sudo apt install graphviz gv |
安装gperftools
下载源码并解压
1 | wget https://sourceforge.net/projects/gperftools.mirror/files/gperftools-2.10/gperftools-2.10.tar.gz |
编译并安装,默认安装在/usr/local目录下
1 | cd gperftools-2.10 |
打开~/.bashrc文件添加环境变量
1 | vim ~/.bashrc |
将目录/usr/local/bin和/usr/local/lib添加进环境变量,在文件末尾追加
1 | export PATH=/usr/local/bin:$PATH |
使~/.bashrc文件立即生效
1 | source ~/.bashrc |
使用gperftools
TCMalloc
简介
tcmalloc全称Thread-Caching Malloc,即线程缓存的malloc,实现了高效的多线程内存管理,对 C 的 malloc() 和 C++ 的 operator new 自定义了实现,用于替代系统的内存分配相关的函数(malloc、free,new,new[]等)。
TCMalloc (google-perftools) 是用于优化C++写的多线程应用,比glibc 2.3的malloc快。
使用方法
方法1:编译源文件时链接-ltcmalloc 库
1
2gcc/g++ [source_file] -g -o [exe_file] -ltcmalloc
./[exe_file]方法2:在运行别人编译好的程序时,可以通过设置环境变量使用tcmalloc(不推荐)
1
2export LD_PRELOAD=/usr/local/lib/libtcmalloc.so
./[exe_file]或
1
LD_PRELOAD=/usr/local/lib/libtcmalloc.so ./[exe_file]
更多信息请见官方文档
Heap_Checker
简介
用来检测 C++ 程序中内存泄漏的堆检查器,检测进程整个生命周期的内存泄露。
heap_checker的检测方式有4种,按检测的严格程度依次为:minimal,normal,strict,draconian ,normal模式适用于大多数内存泄露检查。
使用它有三个步骤:将库链接到程序、运行代码和分析输出。
使用方法(不包括分析输出)
方法1:
编译源文件时链接-ltcmalloc 库,加上
-g选项可以定位内存泄漏的行数1
gcc/g++ [source_file] -g -o [exe_file] -ltcmalloc
设置环境变量并运行程序
1
2export HEAPCHECK=normal
./[exe_file]也可以写在一行
1
env HEAPCHECK=normal ./[exe_file]
方法2:在运行别人编译好的程序时,可以通过设置环境变量使用tcmalloc
1
LD_PRELOAD="/usr/local/lib/libtcmalloc.so" env HEAPCHECK=normal ./[exe_file]
使用示例
leak.cpp
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
using namespace std;
void test1()
{
char *s = new char[5 * 1024];
}
void test2()
{
int *n = new int[2*1024];
}
int main()
{
test1();
test2();
char *s = new char[5 * 1024];
int *n = new int[2*1024];
sleep(3);
return 0;
}使用heap_checker
1
2g++ leak.cpp -g -o leak -ltcmalloc
env HEAPCHECK=normal ./leak输出
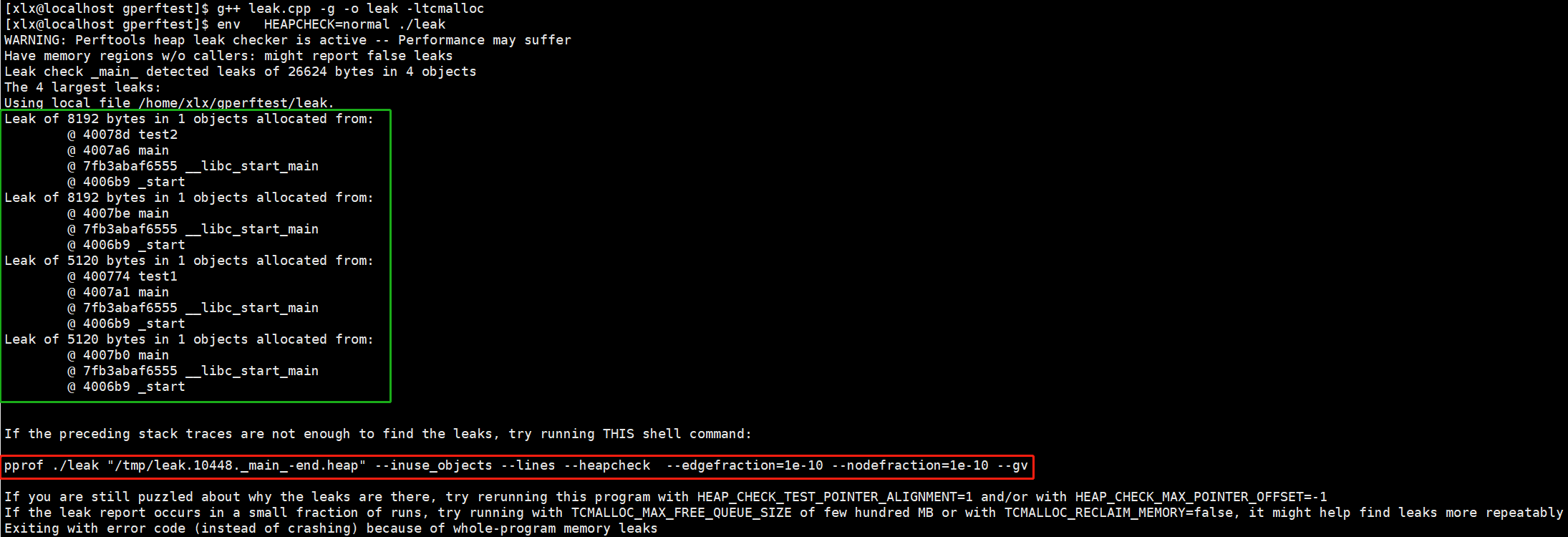
绿框中的输出表示,leak.cpp有4处内存泄露:分别泄露8192bytes、8192bytes、5120bytes和5120bytes另外,heap_checker提示我们可以执行
红框中的语句实现可视化分析通过pprof工具进行可视化分析
1
pprof ./leak "/tmp/leak.10448._main_-end.heap" --inuse_objects --lines --heapcheck --edgefraction=1e-10 --nodefraction=1e-10 --gv
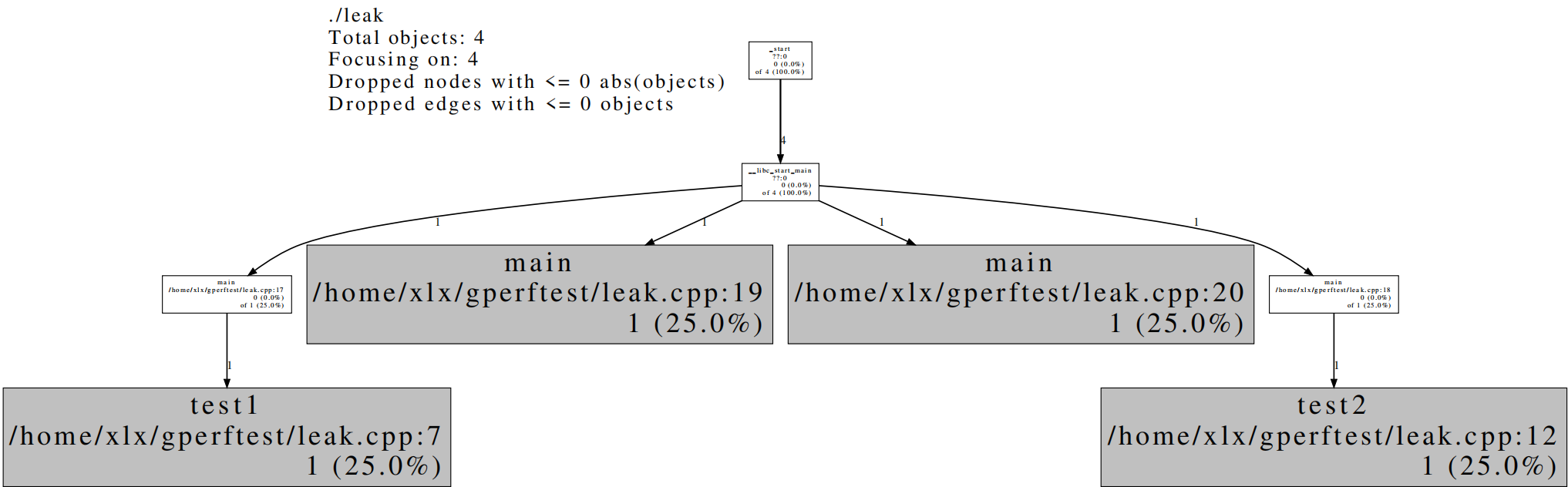
每个
灰色方框表示一处内存泄露,方框包含函数名称、cpp文件位置和内存泄漏发生在cpp文件中的具体行数。指向它们的白色方框中包含的是调用发生内存泄漏的函数的函数信息,也包含函数名称、cpp文件位置和调用发生在cpp文件中的具体行数。由可视化结果可知,发生四处内存泄露:
第一处内存泄漏在leak.cpp的第7行,函数名为test1,这个函数被leak.cpp中的main函数调用,调用发生在leak.cpp的第17行 第二处内存泄漏在leak.cpp的第19行,函数名为main 第三处内存泄漏在leak.cpp的第25行,函数名为main 第四处内存泄漏在leak.cpp的第12行,函数名为test2,这个函数被leak.cpp中的main函数调用,调用发生在leak.cpp的第18行除此之外,可以选择以其他方式查看结果(只需将
--gv改为以下选项)--text生成文字报告--stack生成堆栈跟踪--web以网页的形式展示--pdf生成pdf到标准输出 (较快,推荐)…
更多查看结果的方式请使用
pprof --help命令查阅例如:以text形式查看分析结果
1
pprof ./leak "/tmp/leak.10448._main_-end.heap" --inuse_objects --lines --heapcheck --edgefraction=1e-10 --nodefraction=1e-10 --text

以pdf形似查看分析结果
1
pprof ./leak "/tmp/leak.10448._main_-end.heap" --inuse_objects --lines --heapcheck --edgefraction=1e-10 --nodefraction=1e-10 --pdf > leak.pdf
leak.pdf与gv显示的结果一样
部分调优参数
| 参数 | 默认值 | 说明 |
|---|---|---|
HEAP_CHECK_MAX_LEAKS |
20 | 能打印到 stderr 的最大泄漏数(所有泄漏仍会在 pprof 可视化的时候显示)。 如果为负数或零,则打印所有发现的泄漏 |
HEAP_CHECK_TEST_POINTER_ALIGNMENT |
false | 如果为真,检查泄漏是否可能是由于使用了未对齐的指针造成的 |
HEAP_CHECK_POINTER_SOURCE_ALIGNMENT |
sizeof(void*) | 内存中所有指针应该位于的对齐方式。如果任何对齐都可以,请使用 1 |
HEAP_CHECK_DUMP_DIRECTORY |
/tmp | 内存检测文件的生成位置 |
- 更多信息请见官方文档
Heap_Profile
简介
heap_profile监控程序运行过程中的内存使用情况,会在程序运行时不断生成.heap文件,记录某时刻程序所使用的内存大小和详细信息。
用来分析程序运行中的内存消耗瓶颈,也可以通过比较不同时刻的内存使用量来定位内存泄露。
使用它有三个步骤:将库链接到程序、运行代码和分析输出。
使用方法
链接及运行部分(最终会生成.heap文件)
方法1:
编译源文件时链接-ltcmalloc 库
1
gcc/g++ [source_file] -o [exe_file] -ltcmalloc
设置环境变量并运行程序 (xxx为生成.heap文件的文件名,自定义)
1
2export HEAPPROFILE=xxx.hprof
./[exe_file]也可以写在一行
1
env HEAPPROFILE=xxx.hprof ./[exe_file]
方法2:在运行别人编译好的程序时,可以通过设置环境变量使用tcmalloc
1
LD_PRELOAD="/usr/local/lib/libtcmalloc.so" env HEAPPROFILE=xxx.hprof ./[exe_file]
分析输出
单独分析一个.heap文件(可以选择gv,pdf,text或其他形式显示分析结果):
1
pprof [exe_file] [heap_file] --gv / --pdf > xxx.pdf / --text / ...
将两个.heap文件进行比较:
1
pprof --base=[heap_file1] [exe_file] [heap_file2]
代码插桩
加入头文件,并使用
HeapProfilerStart("xxx"),HeapProfilerStop()可以指定要监督的代码段,本例中heap_profile只会检测代码段2的内存使用情况,并生成xxx.*.heap文件1
2
3
4
5
6
//代码段1
HeapProfilerStart("xxx");
//代码段2
HeapProfilerStop();
//代码段3编译并运行程序
1
2gcc/g++ [source_file] -o [exe_file] -ltcmalloc
./[exe_file]分析输出部分与上文所述相同
使用示例
以treeline为例,在treeline/scripts/ycsb_v2/run.sh中将
1
../../build/bench/run_custom \
修改为
1
LD_PRELOAD="/usr/local/lib/libtcmalloc.so" env HEAPPROFILE=amzn_64B_a_heapprofile.hprof ../../build/bench/run_custom \
并在COND文件中修改实验配置:工作负载为A、记录大小为64B,线程数为16
在treeline目录下,运行
1
cond run //scripts/ycsb_v2:amzn
单独分析一个.heap文件
程序运行过程中,生成了11个.heap文件,分别记录了在运行过程中的十一个时刻的内存使用情况,将其移动到treeline/scripts/ycsb_v2/heapprofile文件夹下
以pdf的形式分析第十个生成文件amzn_64B_a_heapprofile.hprof.0010.heap
1
pprof build/bench/run_custom scripts/ycsb_v2/heapprofile/amzn_64B_a_heapprofile.hprof.0011.heap --pdf >amzn_64B_a_heapprofile.hprof.0010.heap.pdf
生成amzn_64B_a_heapprofile.hprof.0010.heap.pdf文件在treeline/下,可以看到内存消耗较多的函数为
LoadDatasetFromTextFile,ExtractDirty,Put,_M_default_append,优化程序使用内存时可以重点关注这几个函数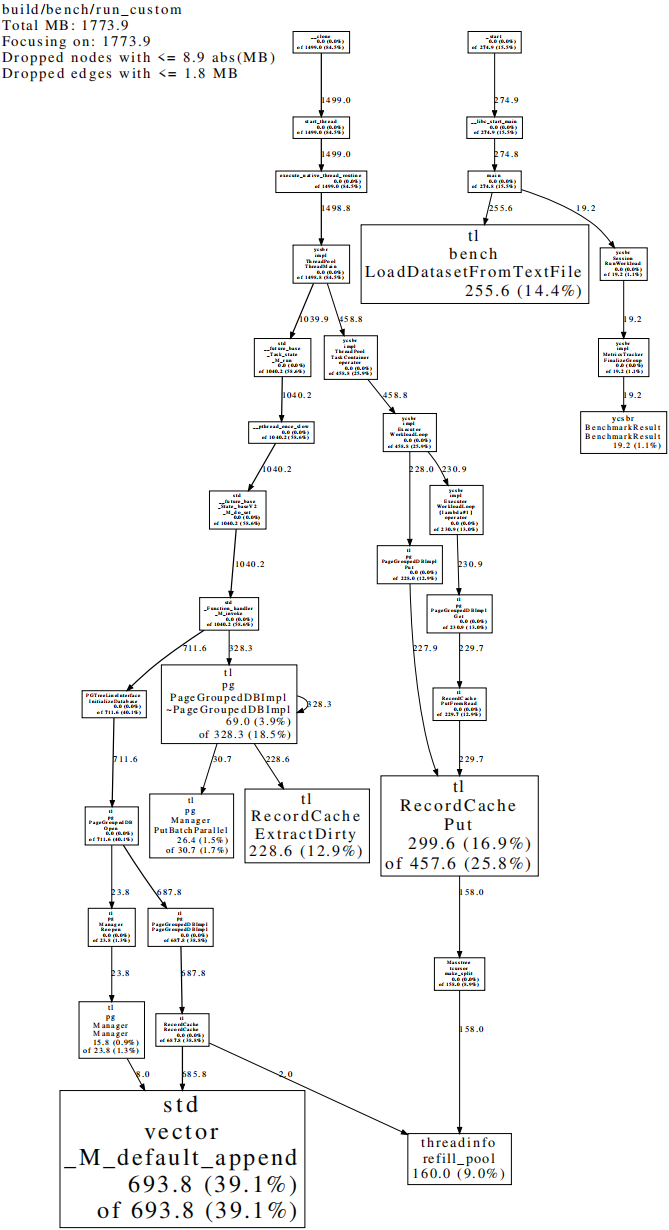
左上角显示元信息:
可执行程序的名称为run_custom,在生成amzn_64B_a_heapprofile.hprof.0010.heap文件的这一时刻,程序总共使用了1773.9MB内存,被关注的函数所占内存为1773.9MB(没有使用
--foucs关注特定函数则默认全部关注),此外,一些不重要的节点和边被丢弃以减少混乱。
有向图所含信息:
图中的每个方框代表一个函数,有向边表示调用关系,有向边旁边的数字代表被其直接和间接调用的函数所使用的所有内存,方框中的信息从上到下依次是:
Class Name Method Name local (percentage) //此函数本身所使用的内存大小(及其占比) of cumulative (percentage) //此函数本身和其直接及间接调用的所有函数所使用的内存大小(及其占比)以下面的amzn_64B_a_heapprofile.hprof.0010.heap.pdf的局部有向图为例:
Manager函数自身使用15.8MB内存,占比为0.9%,此函数本身和其直接及间接调用的所有函数所使用的内存大小为23.8MB,占比为1.3%,其调用的函数所使用的内存为23.8MB-15.8MB=8.0MB;RecordCache函数自身使用0MB内存,占比为0.0%,此函数本身和其直接及间接调用的所有函数所使用的内存大小为687.8MB,占比为38.8%,其调用的函数所使用的内存为687.8MB-0MB=687.8MB;这两个函数都调用了
_M_default_append函数,将两个有向边上的数字相加,得到_M_default_append函数使用8.0MB+685.8MB=693.8MB内存,占比为39.1%;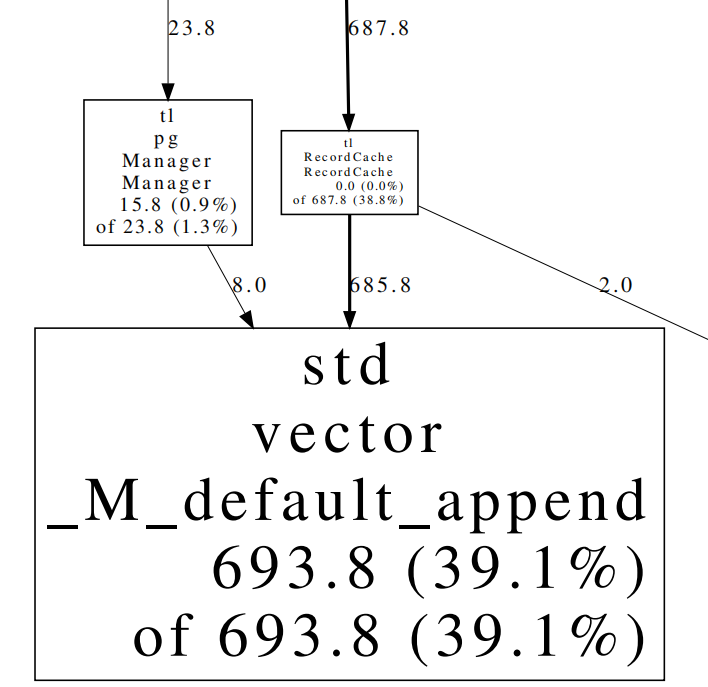
将两个.heap文件相比较
1
pprof --base=scripts/ycsb_v2/heapprofile/amzn_64B_a_heapprofile.hprof.0011.heap build/bench/run_custom scripts/ycsb_v2/heapprofile/amzn_64B_a_heapprofile.hprof.0010.heap
此时会进入交互窗口,输入
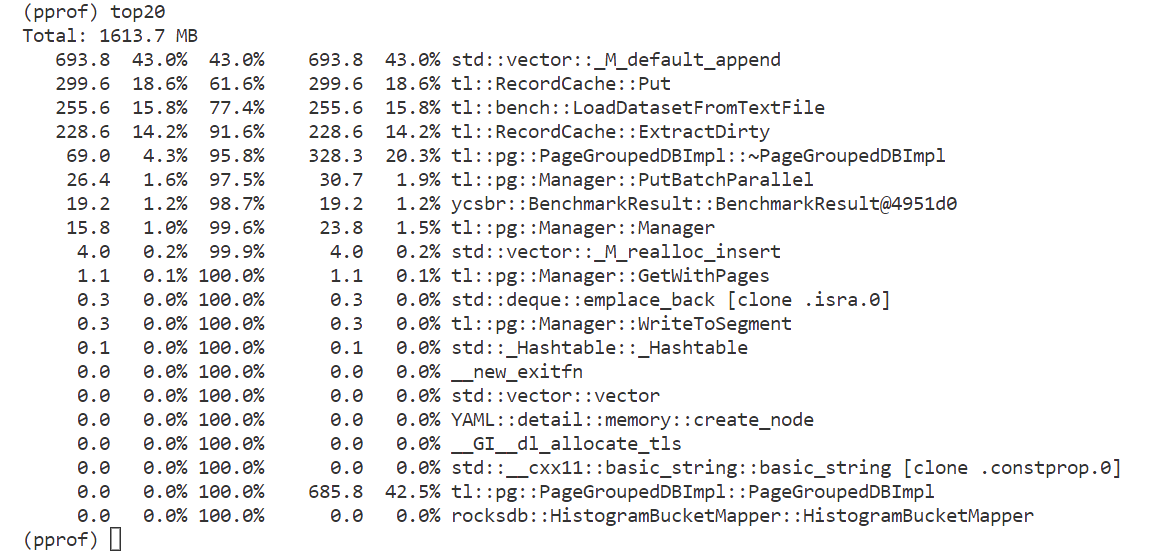
top20,显示前20个内存大小变化最大的函数记生成amzn_64B_a_heapprofile.hprof.0010.heap的时刻为t10,生成amzn_64B_a_heapprofile.hprof.0011.heap的时刻为t11,程序在t10比在t11多使用1613.7MB内存
函数
_M_default_append在t10比在t11多使用693.8MB内存,占1613.7MB的43%函数
Put在t10比在t11多使用299.6MB内存,占1613.7MB的18.6%……
可在交互窗口输入
help查看更多信息更多信息请见官方文档
CPU_Profile
简介
cpu_profile记录程序执行过程中各函数的cpu消耗时间,并生成函数调用图,用来定位热点函数。
使用它有三个步骤:将库链接到程序、运行代码和分析输出。
使用方法
链接及运行部分(最终会生成.prof文件)
方法1:
编译源文件时链接-lprofiler 库
1
gcc/g++ [source_file] -o [exe_file] -lprofiler
设置环境变量并运行程序 (xxx为生成.prof文件的文件名,自定义)
1
2export CPUPROFILE=xxx.prof
./[exe_file]也可以写在一行
1
env CPUPROFILE=xxx.prof ./[exe_file]
方法2:在运行别人编译好的程序时,可以通过设置环境变量使用cpu_profile
1
LD_PRELOAD="/usr/local/lib/libprofiler.so" env CPUPROFILE=xxx.prof ./[exe_file]
分析输出
分析生成的.prof文件(可以选择gv,pdf,text或其他形式显示分析结果):
1
pprof [exe_file] [prof_file] --gv / --pdf > xxx.pdf / --text / ...
代码插桩
加入头文件,并使用
ProfilerStart("xxx.prof"),ProfilerStop()可以指定要监督的代码段,本例中cpu_profile只会检测代码段2的cpu消耗时间,并生成xxx.prof1
2
3
4
5
6
//代码段1
ProfilerStart("xxx.prof");
//代码段2
ProfilerStop();
//代码段3编译并运行程序
1
2gcc/g++ [source_file] -o [exe_file] -lprofiler
./[exe_file]分析输出部分与上文所述相同同
使用示例
以treeline为例,在treeline/scripts/ycsb_v2/run.sh中将
1
../../build/bench/run_custom \
修改为
1
LD_PRELOAD="/usr/local/lib/libprofiler.so" env CPUPROFILE=amzn_64B_a_16_cpu.prof ../../build/bench/run_custom \
并在COND文件中修改实验配置:工作负载为A、记录大小为64B,线程数为16
在treeline目录下,运行
1
cond run //scripts/ycsb_v2:amzn
程序运行结束后,会生成amzn_64B_a_16_cpu.prof文件,记录了在运行过程中各函数的cpu消耗时间和调用关系,将其移动到treeline/scripts/ycsb_v2/cpuprofile文件夹下
以pdf的形式生成结果分析报告
1
pprof build/bench/run_custom scripts/ycsb_v2/cpuprofile/amzn_64B_a_16_cpu.prof --pdf >amzn_64B_a_16_cpu.pdf
生成amzn_64B_a_16_cpu.pdf文件在treeline/下,可以看到cpu消耗时间较长的函数为
GetCacheIndex,__pread_nocancel,__pwrite_nocancel等,说明这几个函数为热点函数,优化程序时可以重点关注这几个函数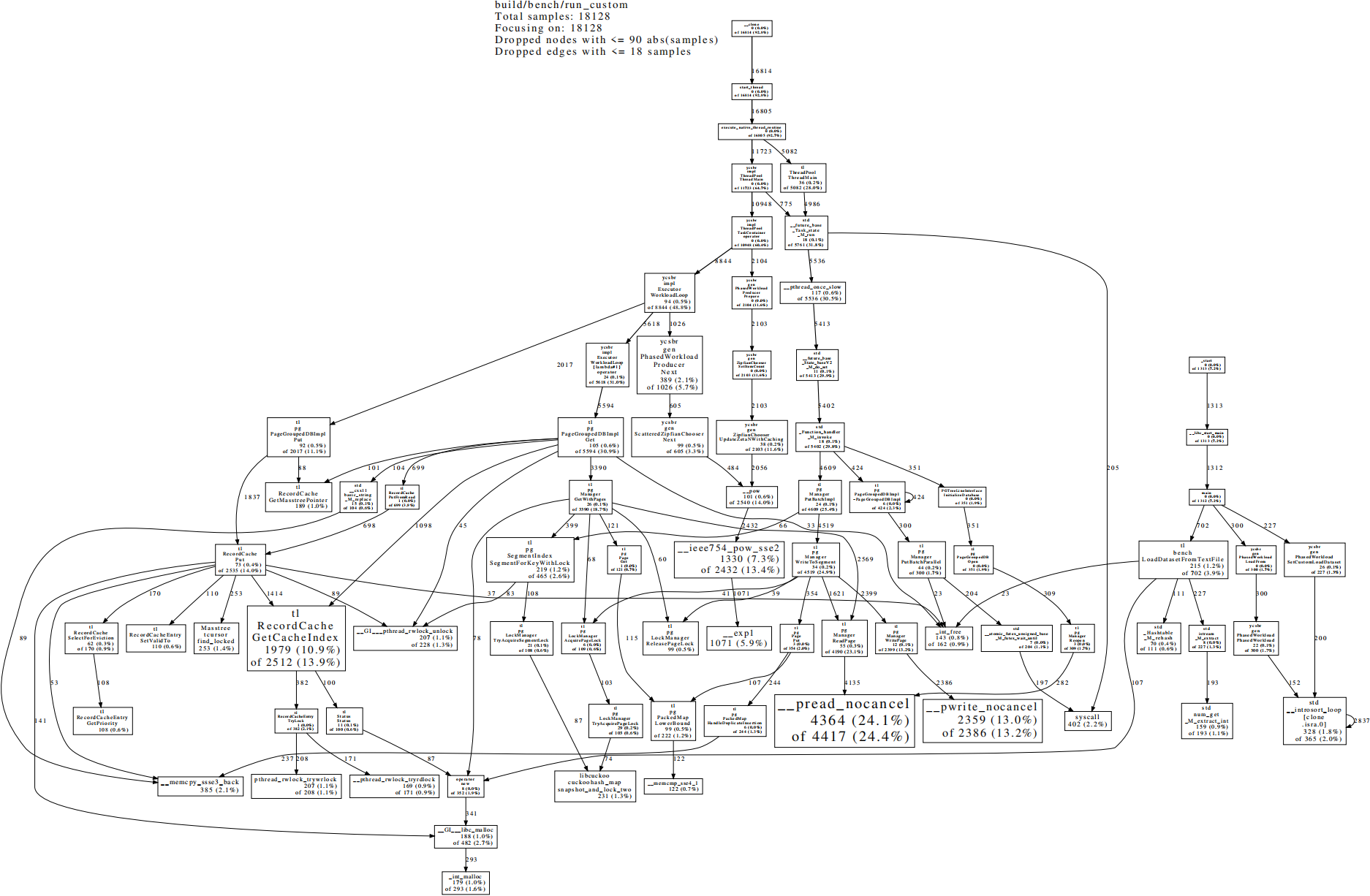
顶部显示元信息:
可执行程序的名称为run_custom,默认每1s采样100次,共采样18128,说明程序执行了181.28s。采样到的被关注的函数次数为18128(没有使用
--foucs关注特定函数则默认全部关注),此外,一些不重要的节点和边被丢弃以减少混乱。
有向图所含信息:
图中的每个方框代表一个函数,有向边表示调用关系,有向边旁边的数字代表采样到的被其直接和间接调用的函数的次数,方框中的信息从上到下依次是:
Class Name Method Name local (percentage) //此函数本身被采样到的次数(及其占比) of cumulative (percentage) //此函数本身和其直接及间接调用的所有函数被采样到的次数(及其占比)以下面的amzn_64B_a_16_cpu.pdf的局部有向图为例:
main函数自身消耗0s,占比为0.0%,此函数本身和其直接及间接调用的所有函数所消耗的时间为13.12s,占比为7.2%,其调用的函数所消耗的时间为13.12s-0s=13.12s;
main函数直接调用了三个函数,分别为
LoadDatasetFromTextFile,LoadFrom,SetCustomLoadDataset;LoadDatasetFromTextFile函数消耗2.15s,占比为1.2%,此函数本身和其直接及间接调用的所有函数所消耗的时间为70.2s,占比为3.9%,其调用的函数所消耗的时间为7.02s-2.15s=4.87s;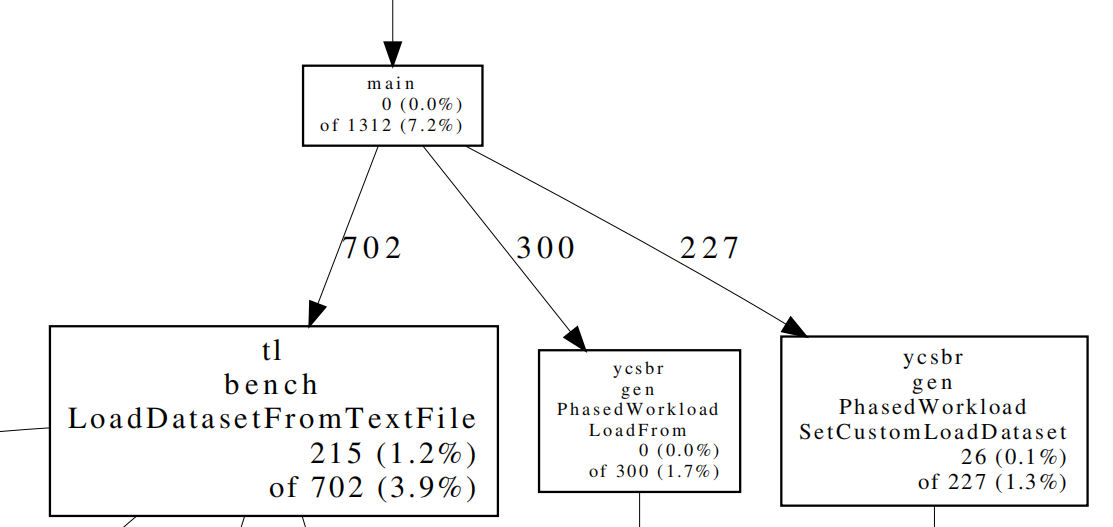
更多信息请见官方文档